
Today, we are excited to share the latest advances with our Business Document Foundation Model as we continue to grow and innovate in the realm of Generative AI for Business Documents. We are announcing two new benchmarks for models that create and label nodes in Business Document XML Knowledge Graphs, as well as results against those benchmarks that outperform OpenAI’s GPT-4 and Cohere’s Command model.
In addition, we are happy to announce today that our multi-modal (vision, text, and semantic structure) Business Document Foundation Model has surpassed all other models of its size on the DocVQA benchmark.
Over the last four years, Docugami has been building the future of documents, creating trustworthy Generative AI technology that that enables frontline business users to surface and repurpose high value data inside their own unique documents with minimal effort. Docugami is already being used by companies across Insurance, Real Estate, Technology, and a wide range of Professional Services.
New Benchmarks for Business Document Knowledge Graphs
One of Docugami's key differentiators is our ability to generate a Document XML Knowledge Graph Representation of your long-form Business Documents, in their entirety – a forest of XML semantic trees representing your unique documents. This enables a much deeper representation of semi-structured documents compared to flat text. The XML tree hierarchically represents the information that is in headings, paragraphs, lists, tables, and other common elements, consistently across all supported document formats, such as scanned PDFs or DOCX. Every document is broken down into chunks of varying sizes, from a single word or numerical value to an address to an entire section or more. Chunks are annotated with semantic tags that are coherent across the entire document set, facilitating consistent hierarchical queries and insights across a set of documents. To provide just a few examples, queries can range from narrow to complex, such as:
- Identifying the Landlord and Tenant details across a set of Leases
- Identifying the Renewal Date across a set of Service Agreements
- Determining if the documents related to a specific jurisdiction have a required Exception Section inside a Termination Clause.
These powerful capabilities can be combined with emerging techniques like the Self-Querying Retriever to enhance answers from individual chunks by attaching the identified information as vector metadata, regardless of context window limitations.
As we broke new ground in this space, we recognized the need to establish new benchmarks for models that create and label nodes in Business Document XML Knowledge Graphs:
- Contextual Semantic Labels for Small Chunks: CSL (Small Chunks) – human readable semantic labels for fields in context (e.g., labeling a date as a “Commencement Date” based on the surrounding text and nodes in the document knowledge graph).
- Contextual Semantic Labels for Large Chunks: CSL (Large Chunks) – human readable semantic labels for clauses, lists, tables, and other large semi-structured nodes in document knowledge graphs (e.g., labeling a table as a “Rent Schedule” based on its text and layout/structure in the knowledge graph).
Unlike classic sequence labeling techniques, these labels are not limited to a fixed set the model was trained on and are uniquely generated for each situation.
We are thrilled to announce that Docugami's specialized Business Document Foundation Model outperforms OpenAI’sGPT-4 and Cohere’s Command on both benchmarks today.
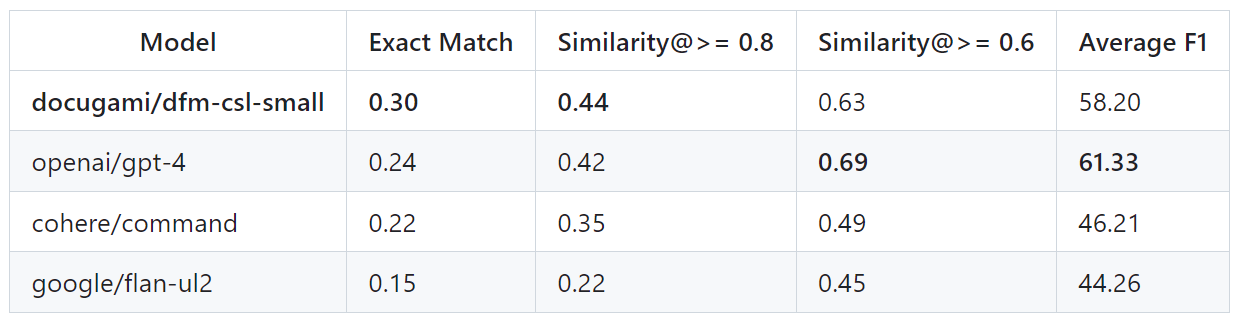
Figure 1: Benchmark Results for CSL (Small Chunks)
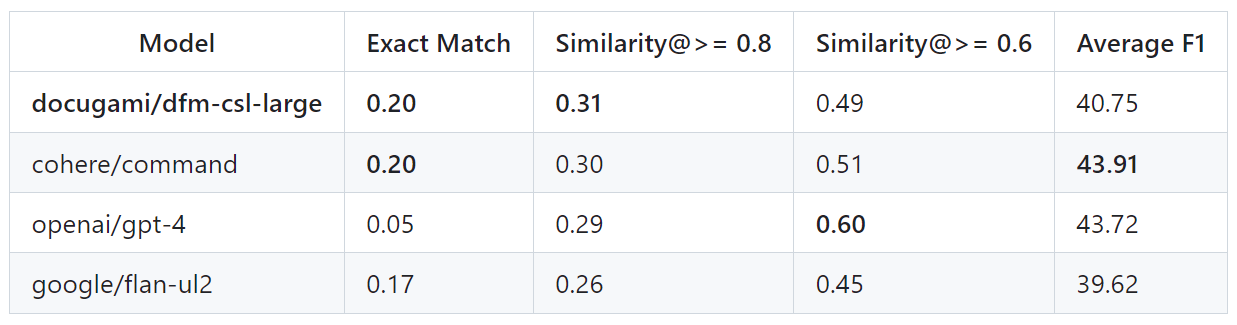
Figure 2: Benchmark Results for CSL (Large Chunks)
This is just the tip of the iceberg. To continue to advance the needs of business users, we need to establish new benchmarks for models that generate Document XML Knowledge Graphs as Docugami does, generating forests of XML semantic trees representing entire documents. That includes, for example, supporting long form documents of hundreds of pages without being limited by an 8K or 32K context window. We will communicate more on this benchmark subject in further posts.
General-purpose large language models can be inaccurate in many business, financial, legal, and scientific scenarios because they are trained on the public internet, which introduces a wide range of low-quality source materials. By contrast, Docugami’s families of LLMs and Layout Models are trained on millions of Business Documents, ranging from 2.7B parameter to 20B parameter models, and fine-tuned exclusively for business scenarios.
Unlike other Generative AI in the headlines, Docugami’s output is generated exclusively from the individual customer’s own documents. By contrast, general large language models like GPT-4 have been shown to “hallucinate,” or make up answers that have no basis in fact but are presented with great confidence and in a format that makes the false answer extremely difficult to detect.
To avoid this issue, every result generated by Docugami can be automatically traced to the specific document and exact text that provided the basis for the result. This makes it easy to review any generated result, provide any missing data, and correct any inadvertent errors that may occur either in the source material or the Generative AI results. And every customer input helps train the unique instance of Docugami’s AI used by that individual customer, making the customer’s system better for each future project. The same cannot be said for a general large language model such as GPT-4, where it is impossible to trace what source information resulted in an inaccurate, inappropriate, or hallucinatory result.
Docugami’s approach also ensures greater customer security, as each individual customer’s unique data is completely confidential, and no information or system learning from one customer’s data is ever shared with any other customer. By contrast, information provided to a public large language model like OpenAI can be incorporated into the model itself, and resurface when the model is used by other customers.
While we are not releasing our proprietary model weights, we are releasing the eval dataset and detailed evaluation methodology on GitHub: github.com/docugami/DFM-benchmarks.
Docugami is available for anyone to use today, and you can try it for yourself to see Docugami in action. We offer a developer API and free trials at docugami.com and welcome discussing those results in our new Docugami Discord.
Document Layout Understanding for Long-form Business Documents
In addition, our multi-modal (vision, text, and semantic structure) Business Document Foundation Model has surpassed all other models of its size on the DocVQA benchmark. We are training larger models that we expect to do even better, but our current model provides cost-efficiency and high performance at scale, which is critical to our customers. This significant accomplishment highlights the effectiveness of Docugami's approach in tackling complex business document understanding tasks.
Our current official DocVQA results are:
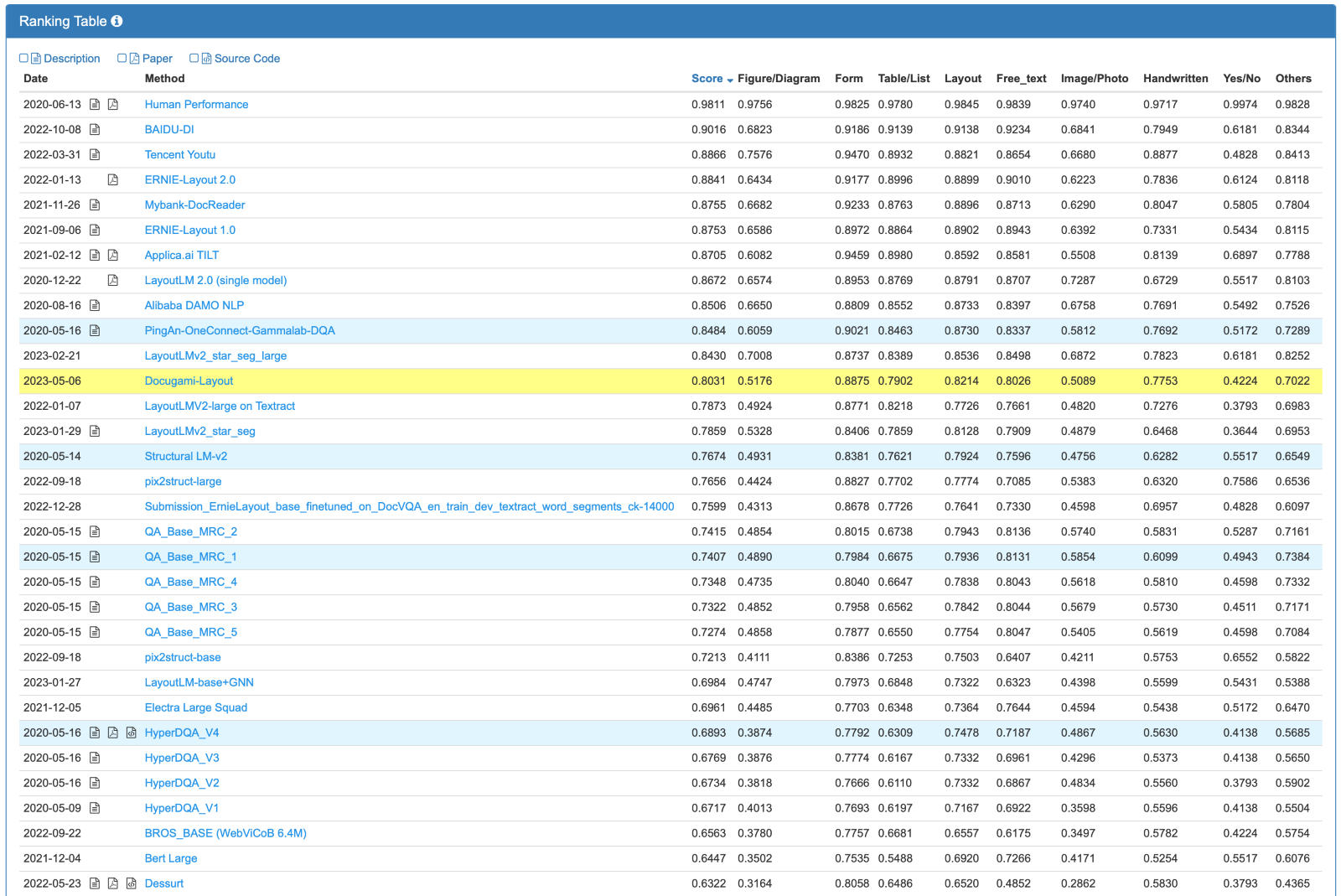
Figure 3: Benchmark results for DocVQA
Exciting Times Ahead
We believe that today’s announcements not only demonstrate the capabilities of our Business Document Foundation Model but also contribute to the broader AI community by providing valuable eval datasets and benchmarks.
Thank you for reading. This is an exciting time in our multi-year journey to transform documents to data. Stay tuned for more exciting announcements as we continue to roll out Generative AI for business documents at scale.