
Loss Run Document Variability
Loss Runs are an inescapable reality in the world of Commercial Insurance. They are a point-in-time representation of a given Insured’s risk profile. They are produced by hundreds of carriers and address a variety of different products/lines of coverage: Property, General Liability, Auto, Excess, Marine Lines, Workers’ Compensation, Professional Liability and more.
They all contain similar information:
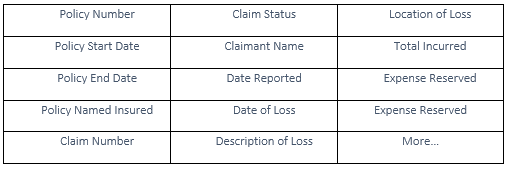
But here's the problem -- the way this essential information in Loss Runs is presented is wildly different from carrier to carrier, product to product, market to market.

This seemingly infinite variability makes Loss Runs one of the hardest document types when it comes to technology options to extract the essential information.
The Information Describes Risk
Carriers, reinsurers and brokers are incentivized to understand the scope and scale of risk, and whether it is commensurate with the premiums collectable in the future. Counterparties are inevitably involved, with different carriers and reinsurers underwriting different products for a given insured.
The whole risk profile is essential to understanding an insured’s risk and the risk posture of the portfolio-at-large.

Software Technologies Have Fallen Short
Classic “intelligent document processing” platforms and purpose-built industry solutions struggle with variability, require continuous reconfiguration, lots of freshly labeled data, and extensive human-in-the-loop review to produce usable structured data streams. This is particularly taxing for organizations looking to have Loss Runs processed the moment they are received.
Until Now
With Docugami, the game changes. Simply upload your documents via our Cloud Storage Connectors (SharePoint, OneDrive, Box or Dropbox) or our REST API. In minutes, we will have these documents processed through our Generative AI pipeline, making them ready for use.
Use our web app to design your project, identifying all the pieces of information you want Docugami to collect on your behalf.
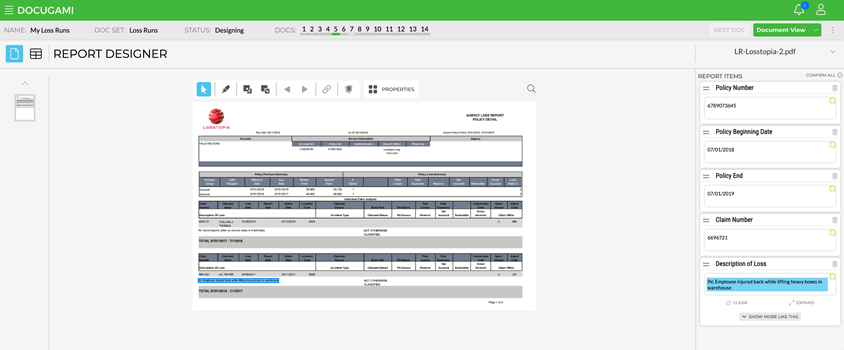
Here is an example of a user telling Docugami in 23 seconds that they want the Policy Number, Policy Beginning, Policy End, Claim Number and Description of Loss:
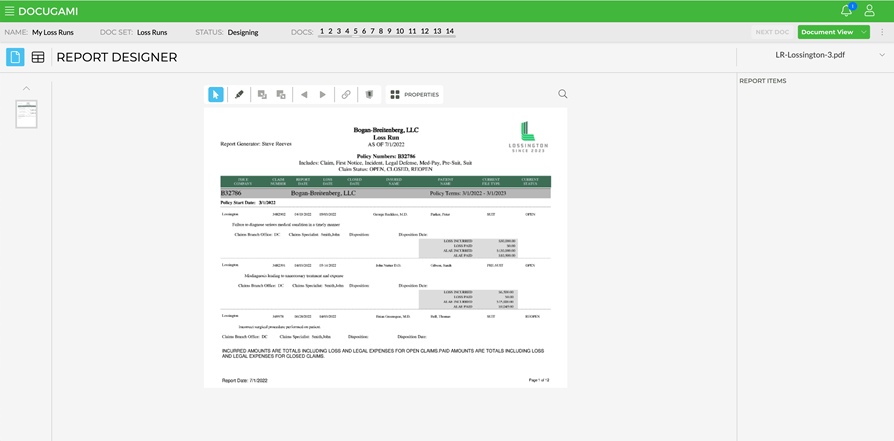
Easy enough, but it is just one fictional Carrier’s template. What about the other Loss Runs from other Carriers in the set? Will we have to configure them too? The answer is no!
Notice how with a radically different Loss Run format, Docugami is able to semantically find the appropriate chunks of information.
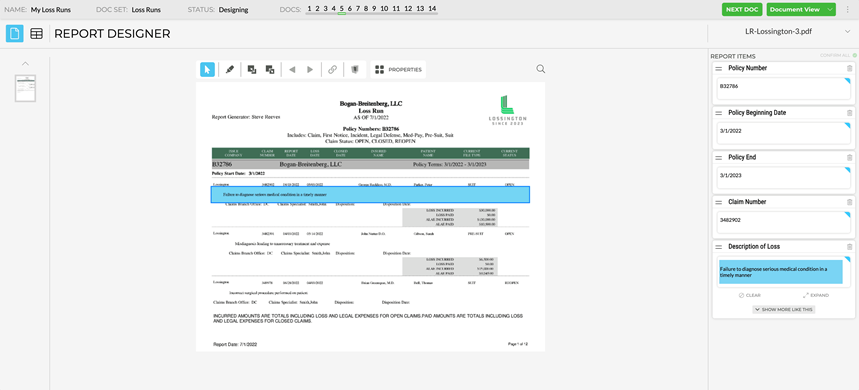
The pattern continues for the next Loss Run as well:
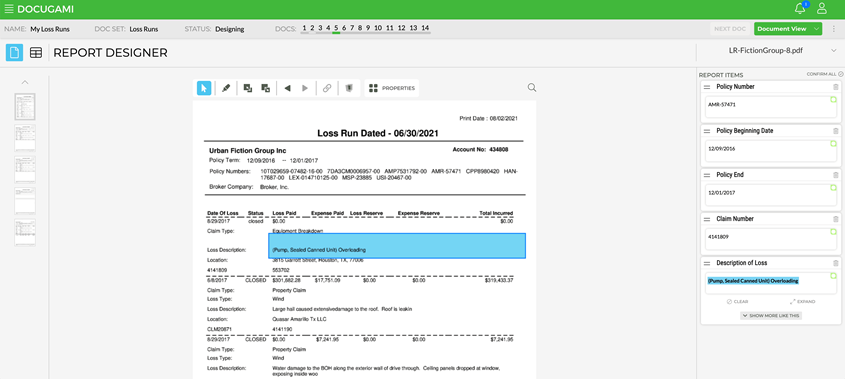
And for every Loss Run in this set, and every future Loss Run that is sent to Docugami for processing.
The Recap:
- Docugami understands the semantics and structure of document information – thus coping with the enormous variability of Loss Runs.
- Users can unlock the vital data from Loss Run documents and create a structured data stream your systems can use, in a matter of seconds.
We encourage you to explore Docugami Generative AI on your own and consider how we can build value with you!
